
The picture above: Many schools today are far more friendly and advanced as schools 40 years ago. Yet, in Hattie’s meta-meta study, schools of different decades are thrown into the same basket to search for statistical effect sizes of ‘what works best’. Picture Credit: Bundeszentrale für politische Bildung.
Introduction: Which factors? Measured how? For which purpose?
Let’s start with a joke about statistics:
Three statisticians went out hunting and came across a large deer. The first statistician fired, but missed, by a meter to the left. The second statistician fired, but also missed, by a meter to the right. The third statistician didn’t fire, but shouted in triumph, “On the average, we got it!”
Averaging effect sizes assumed by a normal distribution can be tricky business. When it comes to people (or deer for that matter), the average only exists as a social construct, an assumed variable that demonstrates reliable efficacy for most members of a given population. In Hattie’s case, however, things get more muddled up as we are dealing with not only different hunters that appear at different times of the day, but hunters who never knew what they were actually hunting for and who, after they randomly killed an unknown animal anyway, by mere chance, concluded a posteriori that they had definitely not killed a deer.
If this sounds like a strange story with loose ends at every stage (to the point of not making any sense), you are welcome to the work of John Hattie who is cited and celebrated, around the world, as a ground-breaking educational researcher. I have written this blog post to allow for a comprehensive online reference to counter Hattie’s omnipresence.
I would not go as far as to accuse Hattie of pseudoscience, as Pierre-Jérôme Bergeron did in his review of Hattie’s statistics, since Hattie does not believe in supernatural forces per se (but omnipotent effect-sizes nevertheless), but I do assess his work as unbelievably sloppy and amateurish science to the point of where he is misleading the public. Other valid comments, such as on Hattie’s flawed statistics, include reviews by Neil Brown or Robert Slavin. Scott Eacott (2017) wrote an illuminating piece on Hattie and the damaging influence of his work on Australian education. For Eacott, Hattie’s work promotes a one-size-fits-all, neo-Taylorist approach to school leadership.
When John Hattie published his book ‘Visible Learning’ in 2008, he intended to pragmatically find out ‘what works best in education’. His basic idea appeared logical: the more studies can be collected about the factors that foster success in learning, the closer science might get to the Holy Grail of education. Hattie had hoped to find universal variables that, once and for all, would scientifically indicate what works best for students to achieve academic success. There are, however, a number of critical conceptual issues that Hattie failed to address. These are listed in the following.
The conceptual issues, in a nutshell
1. Lack of a clearly defined, valid and reliable construct
Hattie never clearly defined the dependent variable, which is student achievement. Since most studies use grades, Hattie (probably) assumed that grades are the smallest common signifier and denominator of students success. Hattie never clarified his all-encompassing variable or how it was concluded. He never explained how the variable of student achievement was constructed (based on which empirical evidence?) and in which context. If he had employed proper scientific methodology, he would have needed to conduct an Exploratory Factor Analysis (EFA) and a Confirmatory Factor Analysis (CFA), leading up to proper Structural Equation Modeling (SEM). Hattie never did any of this. He never defined the dependent variable he actually pretends to measure and which his entire book rests upon. There is no deer to hunt. Hattie is following a wild guess. If Hattie had indeed bothered to clarify the main construct of his study, he would not have been able to throw all studies, regardless of origin, quality or composition, into the grinder of a meta-meta-analysis.
2. The lack of validity of meta-meta studies for educational (and any other) contexts
In ‘Visible Learning’, studies from the 70s and 80s are mixed together with studies from the 2000s. Seriously… can we blindly assume that no progress has been made in schools around the world for the past 40 years? Hattie disregards factors of pedagogical development and culture, public policy changes, historical and socio-economic circumstances. There is no scientific evidence on the validity of meta-meta studies
Another good example of how blind (and rather naïve) quantitative data can lead to misleading analysis is the success of Vietnam in the PISA Studies. John Jerrim wrote a detailed analysis on the topic. The underlying argument says that quantitative analysis can lead not only to wrong but grossly flaky results if contextual factors are not taken into consideration. In the case of the skewed PISA ranking for Vietnam, the flaw was the lack of a proper definition of the sampling population. Hattie is guilty of the same mistake.
Let’s assume for a moment, that Hattie’s could be right by averaging effect sizes of ‘what works’ and extracting the gospel of universal factors for promoting student achievement. If the silver bullets were indeed available, policies would be drawn out in an instant to spend budgets on ‘what works’ while schools would be told to scale back of what doesn’t. So if you happen to work at a school that is not average, according to the almighty meta-meta study, your luck has just run out. As an example, Problem-Based Learning (PBL) rates very low in Hattie’s universe of effect sizes, whereby in Medical Education, it has empirically proven to be significantly superior to traditional approaches and has been, for decades, firmly established as a State-of-the-Art pedagogy (see Wang et al., 2016; Sayyah et al., 2017; Zhang et al., 2015).
3. The limitations of effect size to inform pedagogy
Let’s assume that we compare apples with apples and oranges with oranges, in which case we can argue with effect sizes based on the average, e.g., the average size of a typical apple or orange, grown on a particular orchard. The average gives us, well, just the average. It does neither tell us the size of the smallest, nor of the biggest apples or oranges. Averages do not tell, how and why, the best and the worst students perform as they do.
But what is the basis of effects? Did students have 20 minutes for a test or were they given a full hour? Had a test been based on mere rote-learning or was it based on problem-solving and developing creative strategies? Has a school project been conducted as an individual task or as a group project? Was a lesson designed more in an instructional or more in a constructivist manner, or as a mix of both? And if yes, was this mix adequate and efficient to foster student learning? Hattie does not bother with such trivialities. In order to compare measurements, one has to ensure that the instruments to take those measurements are at least comparable.
For Hattie to claim that one educational practice is per se ‘good’ (= large effect size) or per se ‘bad’ (= small effect size) defies all foundations of pedagogy. Didactic context is not considered in his work. A validated psychological or motivational model is absent in ‘Visible Learning’ as well. In order to make sense of any effect size in the context of classrooms, the inclusion of pedagogical and didactic models is a condicio sine qua non. An effect without context does not make any sense.
Below: Effekt sizes according to Hattie
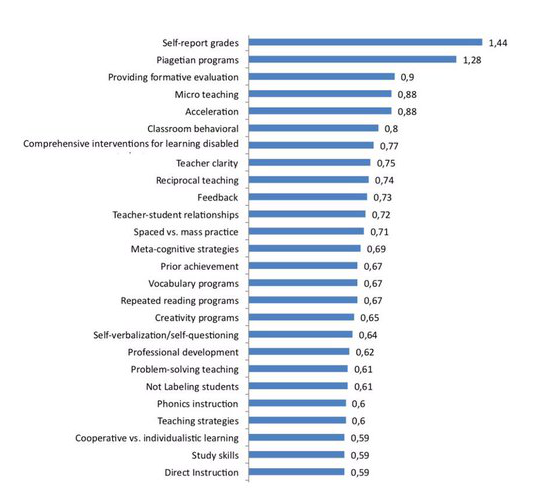
4. Hattie’s self-contradiction
In concluding his book, Hattie differentiates between surface knowledge, deep knowledge and conceptual knowledge, all of which are regarded as essential. Hattie concludes that 60-80% of all knowledge created by tests, evaluations etc., qualifies merely as surface knowledge. This means that only 20-40% of all knowledge taught by teachers, passes as deep- and conceptual knowledge. Besides making a fairly bold statement – if this was indeed true, then all of Hattie’s measures of effect sizes would be practically meaningless: Once teachers intend to achieve deep- and conceptual knowledge, they would change their teaching strategies based on Hattie’s recommendations. In this case, predictably, most effect sizes would change significantly (!). This dilemma reveals another flaw of his research: Hattie uses data ‘as is’ (which he later identifies as predominantly inefficient teaching) but uses the concluded effect-sizes from the same data sets to formulate a hierarchy of best practices. Things cannot be valid (efficient teaching) and invalid (inefficient teaching leading to surface learning) at the same time, can they?
Hattie’s cult following should not distract from the fact that Hattie has neither contributed to the development of modern pedagogy nor has he informed sensible school policy. If I was looking for an inspirational figure (or charismatic guru) with a superior grasp on the dilemma of educational systems, I would look for someone like Sir Ken Robinson, or would professionally study constructivist pedagogy. Not all of Hattie’s writing is misguided. To give a more balanced review, I would need to mention his sensible ideas on feedback etc., but then again, these topics have been researched far better by others.
5. It isn’t statistics
School grades, the only data available in Hattie’s Visible Learning to measure academic achievement, are set as ordinal scales. In order to calculate effect sizes with Cohen’s d (the standardised difference between two means), one would need at least an interval scale. This is how Hattie’s calculations might be something, but it sure isn’t statistics.
Literature
Hattie, J. (2012). Visible learning for teachers: Maximizing impact on learning. London: Routledge.
Scott Eacott (2017): School leadership and the cult of the guru: the neoTaylorism of Hattie, School Leadership & Management, DOI: 10.1080/13632434.2017.1327428
Zhang Y, Zhou L, Liu X, Liu L, Wu Y, Zhao Z, et al. (2015) The Effectiveness of the Problem-Based Learning Teaching Model for Use in Introductory Chinese Undergraduate Medical Courses: A Systematic Review and Meta-Analysis. PLoS ONE 10(3): e0120884. https://doi.org/10.1371/journal.pone.0120884

As i read this article, a kind of form or pattern started to emerge – three quarter through i began to wonder how my teacher (as an adult learner) would have assessed Hattie’s work. A question then arose: If i download his materials and search the terms ‘authentic learning’ and ‘creativity’ how many hits would there be over the terms ‘education’ and ‘teaching,’ for example.
By near the end i almost laughed with joy to see you offer an alternative person as an exemplar – Ken Robinson.
The word ‘deep’ (depth) counts for a lot in the way i understand effective and creative learning.
Thanks for publishing this!
A
Dear Andrew,
I agree with you whole-heartedly on the importance of deep learning. I do believe that Hattie has good intentions, as most educators have. The problem with Hattie and his cult-following is the assumption of a one-size-fits-all model, which has terrible political implications and consequences. As for Ken Robinson – what would the world be without people like him? I believe that we can actually search (as per your suggestion) keywords, such as from journals, and put them into a network model based on their publication date. A professor at Oldenburg University did this for the area of digital education recently (Zawacki-Richter, 2016), and it validates your idea. Not all is doom and gloom. In terms of education, considerable progress has been made over the past decades. We just have to push with far more gusto for reforms and funding.
My Kindest Regards!
Joana
Zawacki-Richter, O. (2016) Mapping research trends from 35 years of publications in Distance Education. Taylor Francis online https://www.tandfonline.com/doi/abs/10.1080/01587919.2016.1185079